Table of Contents
The Blinking Computer
The Blinking Computer will be a reasonably easy-to-build educational computer. As the name suggests, the idea is that you can write code and see it execute at every level, that means discrete components and lots of LEDs. The design has evolved many times since the 1980's. If you like this sort of thing you'll probably also like the Homebrew Computers Website and howcpuworks.
The objectives are:
- Simple enough so that everyone can see how it works, that means lots of LEDs
- Complex enough to demonstrate the main ideas of a computer
- Small enough to be affordable by anyone with the time to build it
- Quick enough to build and keep my (and those that follow me) family life
- Fast enough to run some complex software
- Slow enough so that everyone can see it running and understand it step by step
- Flat enough so that the entire state can be seen in one go and can be hung on a wall
Overview of Hardware and Software
The Blinking CPU uses a very simple design. There are eight registers, one of which is the program counter. On every instruction cycle the program counter is incremented, two registers are passed through the ALU and stored in a third register. Each register access has an indirect mode, meaning that the value at the address held in the register can be used to load a value for the ALU and the ALU result can be stored at a value held in the destination register. Everything is 16 bits wide: the instructions; the registers; the address space and the words in memory.
The ALU only implements addition, subtraction and a few basic logic operations, there is no multiplication or division. There is a carry flag, a zero and a negative flag. The addition and subtraction operations can be conditional, which implements control flow by conditionally writing to the processor register.
The CPU is predominantly built using Resistor Transistor Resistor Logic in a straightforward manner. However, there is the need to build time and parts cost and so two areas tend on the side of minimalism over understandability, even though the primary aim is education. The memory is a two transistor DRAM cell using a MOSFET as a storage capacitor, and the ALU uses a novel adder to mimimise the ripple carry delay. The intention is to simulate all parts with Circuit Lab and so be able to explain without the need for an oscilloscope.
The RAM uses a Raspberry Pi Pico. In some senses it would be ideal to build RAM as well, however the implementation of the registers already provide the educational aspect of this, and the goals on assembly time and cost override the ideal of using discrete transistors and LEDs everywhere.
As the assembler is only one instruction, it's easy to learn and maps directly to what happens on the hardware. A minimal FORTH is provided so that complex systems may be thrown together quickly, as well as providing 32 bit operations and missing functionality such as multiply and divide. A very minimal language is provided that compiles to FORTH which is compatible with Python syntax. This is again kept very simple so that the process of compiling may be understood. All software, including the emulator, is open source.
The rest of this document starts at the transistor level and works through to high level programming. It's equally possible for students to start by writing some simple code in the emulator, inspect it at every level down to machine code, then see that machine code execute as Blinking LEDs.
Hardware
Memory cell
At present the only writeup is on hackaday.io
Arithmetic Logic Unit
The ALU implements the standard AND, OR, XOR bitwise operations, plus Logical Shift Right (LSR) by one.
Only addition and subtraction are supported as arithmetic operations, a carry input may be used.
Subtraction is just inversion and then addition with the appropriate carry flag. Addition/Subtraction not only take up the largest number of gates per bit, but are also the only instructions where the bits are not processed independently. Ripple Carry is implemented for simplicity (faster algorithms exist), this means that addition/subtraction is the slowest ALU operation. The worst case performance is where the carry has to propagate the whole length of the word. In an instruction cycle the program counter must be incremented, thus the ripple carry adder is the main constraint on the system speed.
Pass Transistor Logic can be used to reduce the complexity. For example, XNOR can be be implemented with only two transistors. A full adder is only two cascaded XNOR plus the carry mechanism. For inputs A and B with carry C we have:
| Input A | Input B | CarryIn C | D = A XNOR B | Out = C XNOR D | CarryOut |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 |
Note that CarryOut = A IF D ELSE C, that is if D is zero then the carry is propagated, else it's set to the value of A (or B). This is the idea behind ''diode carry'' where the carry signal propagates only through fast diodes and so improves the worst case performance of the ALU. The diode carry idea is from 2017 but has yet to be implemented.
Instruction set
All instructions are of the form cnd [*]DST = [*]SRC0 OP [*]SRC1 where:
SRC0,SRC1andDSTare registers or constants. There are 8 in total consisting of:- P the Program Counter, this is incremented on every instruction and may be written to
- A, B, C, general purpose registers
- 0, 1, 2, 3 which are constants
[*]Ameans either direct addressing,Aor indirect addressing,*A- *P is the next word to be read, which may be an instruction or an immediate value to load into a register, e.g.
X = *P. Jump absolute is P = *P which jumps to the next word after the instruction being executed - *0 is the memory at location 0, and therefore *0, *1, *2 and *3 can be used as registers
- ALU operations are below.<WRAP>
^ example ^ description ^
| A = B AND C | bitwise AND |
| A = B OR C | bitwise OR |
| A = B XOR C | bitwise XOR |
| A = B ADC C | addition without carry |
| A = B SBC C | subtraction without carry |
| A = B LSR C | Logical Shift Right - currently only implemented for C = 1 |
| A = HCF | WHATEVER HAPPENS, DO NOT CALL HCF! |
| A = B ADD C | addition without carry - conditionally executed |
| A = B SUB C | subtraction without carry - conditionally executed |
</WRAP>
cndis conditional execution which may be applied to the+and-OPs, the four cases are given below. In practice, eq0 and ne0 are equally used, although one could be eliminated with the XOR instruction. Of gt0, ge0, lt0 and le0 only lt0 is implemented as it's the most common. The others tend to occur after a subtraction, reversing the subtraction order gives ge0, and setting the carry bit and using SBC gives gt0 and le0.<WRAP>
^ cnd ^ description ^
| always execute - this is the default case | |
| lt0 | execute if the previous ALU result was negative |
| eq0 | execute if the previous ALU result was zero |
| ne0 | execute if the previous ALU result was not zero |
</WRAP>
cndandOPare 4 bits total,[*]SRC0,[*]SRC1and[*]DSTare 4 bits each giving a total of 16 bits
Short form instructions
| short | long | comment |
|---|---|---|
| [*]DST = [*]SRC0 | [*]DST = [*]SRC0 + 0 | this runs the ALU and effectively ignores the second argument |
| [*]DST = word | [*]DST = *P, word | load immediate. The next word is the data to be loaded |
| JMP word | P = *P, word | loads P with the next word |
| CLC | 0 = 0 ADC 0 | clears the carry flag |
Hardware implementation of the instruction set
There are two levels to the state logic in the CPU. At the top level, the CPU executes an infinite loop of:
program counter increment and instruction fetchexecute from instruction register
Most processors ensure that instruction fetch and program counter increment happen concurrently with the instruction execution. The Blinking CPU favours simplicity over speed, making this loop explicit allows reuse increment hardware. The special instruction register is hard wired into any write in the first phase of this loop.
For each instruction the low level pipeline is:
- check the instruction is to be executed (
cnd), if not then skip the rest of this list (MCRESET) - place
SRC0on the register address bus (RADDR = SRC0) - the Pico reads the register read data bus (PICOADDR)
- if
*SRC0then the Pico overrides the values with*SRC0(ALU0READ=1, PICOINDIRECT) - store the the register read data bus in ALU0 (ALU0READ=0) and place
SRC1on the register address bus (RADDR = SRC1) - the Pico reads the register read data bus (PICOADDR)
- if
*SRC1then the Pico overrides the values with*SRC1(ALU0READ=1, PICOINDIRECT) - store the the register read data bus in ALU1 (ALU1READ=0) - the ALU now has final values
- place DST on the register address bus (RADDR = DST)
- the Pico reads RADDR and if incrementing P writes the instruction register
- wait many cycles for the ALU (ripple carry is slow)
- if *DST: the Pico reads the register read data bus and if *DST then stores ALU output
- if not *DST then write to the register on the register data bus
The instruction pipeline is long. This is because the conventional READ, WRITE and ALU instructions have been merged into one single instruction. Speed is not a objective here, getting the design simple enough to understand and get built is what counts. In contrast, here is the 6502 architecture and this is what it looks like when running.
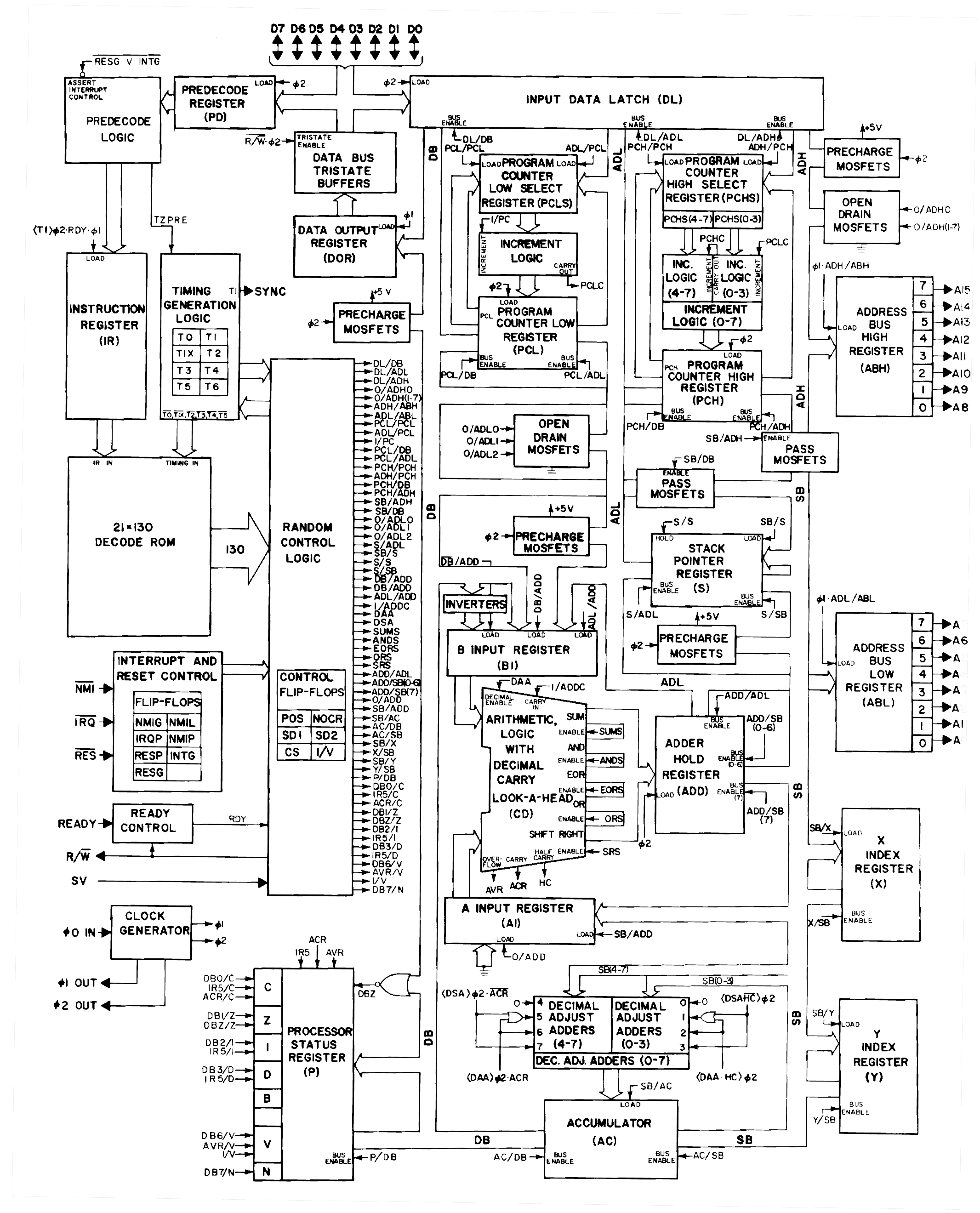{kind=link}
Here the Pico is only acting as memory. Conventionally memory has an address bus and a data bus, however the Pico has 24 GPIO pins available and so does not have enough pins for both address and data bus. Hence, the address is read first followed by a read/write to the data bus using the same GPIO pins. The Blinking CPU is set up for the Pico to read at every opportunity, whether the information is needed or not. This allows for the Pico to be running an emulation of the CPU for debugging and fault finding.
Load immediate and the NOP flag
The next word in the instruction sequence can be loaded with *P and used as a general 16 bit value. This needs a bit of hardware support to ensure that this 'load immediate' word is not also taken as an instruction in the next cycle. The processor contains a NOP flag which is set if the instruction contains *P except when the destination is P and the instruction is executed. The NOP flag clears on the load of the next instruction. This doesn't skip the word that has been read, it just means that the processor reads it and treats it as a conditional instruction that doesn't execute which is an acceptable overhead.
Memory
The CPU has a 16 bit address space and 16 bit data space. A Raspberry Pi Pico is used to store the 65,536 words of memory as it is low cost and very well supported for educational use. The Pico doesn't have enough GPIO pins to separate the address bus and data bus, so this is shared.
In future the Pico may:
- Track all read/writes to the address registers to error check that the processor
- Display the contents of memory on a VGA monitor so that even the RAM is visible (many columns of 16 bits)
FORTH
FORTH is a very lightweight language popular as a first language after assembler for very low resource hardware - so perfect.
This project has a partial and fairly mutilated implementation of FORTH. No apology is made for this, FORTH is not a good language for learning to code. At this stage it's use is to stress test the instruction set and the hardware, to find out what doesn't work and to find out what features are missing or aren't used.
FORTH is normally self-hosted, there's an 'outer interpreter' written in FORTH that reads characters, splits into tokens, looks up tokens in a dictionary and writes FORTH code. This project doesn't do that, it uses a far more conventional parse and compile approach. The compiler tools generate a memory image which is loaded into the memory and the processor is reset to run the code.
Also FORTH is normally implemented as threaded code with an inner interpreter, the details of which is often quite hard to understand. Hence first we present an interpreted implementation which sets out the data structures and the extra complexity of threading is discussed later. In both cases:
- A is the execution pointer, it points to the address of the function to execute next
- B is the data stack which grows upwards. *B is the top of the stack that contains the item of data.
- C is the call stack which grows downwards. *C is empty, *(C+1) is the execution pointer in the parent function. To recurse, the execution pointer is saved on the call stack with
*C = Aand the execution pointer is set to the first item in the called function,A = *A
FORTH uses the term 'word' for a function/subroutine. We reserve the term 'word' for the more conventional usage of the natural data size, whatever it contains, and use the term 'function' for function/subroutine. In standard FORTH all functions take their arguments from the stack (B) and return results on the stack. We divide functions into primative functions that are written in assembler and compound functions which are a list of primitive and compound functions.
Interpreted FORTH
This is the easiest case to understand and so is presented first. Here is the interpreter, all the primitive functions (written in assembler) live below asmForthBoundary, all the compound functions live above it:
*3 = asmForthBoundary
interpreter:
A = A ADD 1 # point to the next function to be executed
0 = *A SUB *3 # set flags to say if this is assembler or a compound function
lt0 P = *A # if assembler then call it directly
*C = A # if compound then store the current function on the call stack
C = C SUB 1 # make some space
A = *A SUB 1 # and start on the new list of functions
P = interpreter
Primitive functions must preserve A, B and C registers (as they are neeed as above) but may freely use *0, *1, *2 and *3. Primitive functions simply return by jumping to the interpreter label as A and C keep track of what to do next. For example, in this scheme we can define dup as:
dup: # duplicate the top of stack *0 = *B # copy top of data stack B = B ADD 1 # increase data stack *B = *0 # write duplicate P = interpreter
A compound function looks like:
: dup2 dup dup ;
which compiles very simply to a list of address of functions:
dup2: :dup :dup :return
and the return function just pops the call stack and set A:
return: # return from a list of functions C = C ADD 1 A = *C P = interpreter
Threaded FORTH
Most FORTHs use some form of threaded code where the tail of one function looks up where to go next and jumps directly to that. This avoids jumping back into the interpreter just to increment the execution pointer and then jumping out again. This is easiest to understand in a primitive function as all that is needed is to increment the execution pointer to point to the next function and jump to it.
dup: # duplicate the top of stack *0 = *B # copy top of data stack B = B + 1 # increase data stack *B = *0 # write duplicate A = A + 1 # NEXT: increment the instruction pointer P = *A # NEXT: jump directly to the next function
Here the code has boilerplate of two instructions at the end whereas the interpreter code only had one, however there were also three instructions to call the primitive function. Consequently the threaded version is faster as the 2 instruction overhead is less overhead than 4 for the interpreter. In practice, some of the A = A + 1 can be eliminated so threading primitives has very low overhead for this instruction set.
For compound functions we must start up the 'inner interpreter' on every function:
dup2: *C = A + 1 # docolon: push the incremented execution pointer onto the call stack C = C - 1 # docolon: increase the (descending) call stack A = P + 1 # docolon: Execution pointer to start of function list P = *A # docolon: start executing the first function :dup :dup :return
The return function is almost the same and executes in the same number of instructions:
return: # return from a compound function C = C + 1 A = *C P = *A
Comparing the two implementations for compound functions, the interpreter has 7 instructions in the loop whereas the threaded implementation only takes 4 instructions to start, therefore the threaded implementation is faster for both primitive and compound functions. As there is more boilerplate code for the threaded implementation the memory usage will be greater, but hey, there's a whole 64k words to play with and that's massive.
NOTE: *C is empty, so it's possible to keep the instruction pointer in *C and not use A. However, an indirect through the instruction pointer is needed in the NEXT code, so not using A increases this code from two lines to three lines (*C = *C ADD 1; A = *C; P = *A). If A is needed in a primitive function it can always be stored in *C and *C used in NEXT without penalty, so that's what's done as it results in shorter or same length code.
Types and naming convention
Most functions operate on a word and are independent of what that word contains. For integers, S1, S2, U1, and U2 are supported, where S/U donates signed and unsigned and the digit indicates the number of words used. Therefore U4 is a 64 bit unsigned integer. The floating point types are F2 and F3. F2 is IEEE single precision and F3 has a faster, unpacked format with extended range. Operations are implemented in F3 with F2 only supporting conversion to/from F3.
SIMPL
SIMPL is a SIMPL IMperative Procedural Language. It's deliberately minimal and very very simple - the aim is to show how languages and compilation work in an easily digestible way. It looks like a tiny subset of Python.
The language implements the absolute minimum and so can be mastered very quickly. Variables can be global or local to functions, only fixed sized arrays are supported. Types are as FORTH with the default being a 32 bit signed integer (S2). There are ten infix operators (+, -, *, /, ==, !=, <, >, <= and >=) for familiarity and readability, but no operator precedence and so order must be explicitly stated using parenthesis. if/elif/else and while/break/continue exist for control flow using indent for scope and that's it. The code below was the first real use of the compiler (04Aug23):
# algorithm from https://bisqwit.iki.fi/story/howto/bitmath/#DivAndModDivisionAndModulo
def divmodU2(dividend, divisor):
multiple = 1
while divisor < dividend:
divisor = divisor + divisor
multiple = multiple + multiple
result = 0
while multiple != 0:
if dividend >= divisor:
dividend = dividend - divisor
result = result + multiple
divisor = lsr2(divisor)
multiple = lsr2(multiple)
return result # , dividend
Global/Local variable declarations
A variable is declared and type assigned on first usage. Further usage should not specify the type. Global variables are visible in functions and must not conflict with local variable names or function argument names. Function arguments are assumed to be S2 unless a type is provided.
SIMPL and Python
The target audience for the Blinking Computer is learners in Electronics and Computer Science and Python is regarded as being the best first language to learn. Therefore SIMPL was designed to be as compatible with Python as possible in order to minimise the conflicts in learning both of them. However, SIMPL also has the goal of being a very small self-contained language where it is possible to understand all the steps in compulation to bytecode (FORTH), machine code, instruction execution down to individual states and blinking lights. However, there are inevitable differences:
- SIMPL has very few language constructs, it's meant to be simple
- SIMPL is static typed, Python is dynamic typed
- SIMPL has no library support
- SIMPL is designed to work with the Blinking Computer only
Therefore it is worth listing the pros and cons of keeping the two aligned:
PROs:
- A clean, easy to understand syntax
- It minimises the conflicts with a language they will know or learn soon
- It makes the point that there's nothing magical about Python, it appears possible to extend SIMPL and get Python
- If the compat module is loaded then SIMPL is accepted by the Python interpreter which should aid debugging
CONs:
- Learners will want to use other Python features they know, the compiler is not forgiving, this could get confusing
- lack of operator precedence or dynamic typing may lead to bad habits when programming Python
It will be open for review whether this 'almost a subset of Python' is the right way to go.
Q and A
Q: Why a general purpose register based architecture not an accumulator based architecture?
A: The accumulator based architecture was tempting, it keeps the complexity down which keeps the build time and cost down. However, this only happens if the number of registers is reduced to the accumulator, the program counter, status register and pretty much nothing else. It was important that the assembly level should feel like a modern processor with general purpose registers. The current design only has four, which should be roughly in balance with the complexity of the ALU, plus general purpose registers allows for writing to the program counter and thus a unified instruction set.
Extensions
The Blinking Computer is designed to be minimal with lots of holes to fill. It's a starting point for other work, some of which could be:
- Bugs:
- Find a bug, learn how to file a bug report as an Issue in git
- Pick a bug, fix it, report the fix
- Learn the basics of git, make a pull request with the bug fix
- Use the Pico to emulate the processor and halt on any discrepancy
- Swap out the slow ripple carry for something faster, maybe my diode carry
- Extend the instruction set, for example:
- replace HCF by something more useful
- an indirect indexed mode so
[*]DST = [*]([*]SRC0 OP [*]SRC1)
- Dump memory to a VGA monitor or a LCD panel so that all the state can be seen
- Allow paged/shadow RAM (like the BBC Micro)
- Write a 6502 emulator just to be retro, maybe even run BBC BASIC
- Look at other concatenative languages
- Rewrite the SIMPL compiler to be bullet proof and always give informative error messages (it's intended for beginners, it should be better)
- Extend the SIMPL language to include more of Python